
3과목 출제 유형 분석
📊 빅데이터분석기사 주요 출제 영역
- 머신러닝 기초 이론 (30%)
- 통계 분석 기법 (25%)
- 딥러닝 및 신경망 (20%)
- 데이터 전처리 (15%)
- 모델 평가 및 검증 (10%)
📈 출제 경향
- 이론과 실무를 균형있게 다룬 문제 구성
- 개념 정의보다는 적용과 해석에 중점
- 최신 머신러닝/딥러닝 기법 포함
- 실제 데이터 분석 상황을 반영한 문제
빅데이터분석기사 3과목 기출 문제 (41번~60번)
41. 다음 hierarchical clustering dendrogram에서 distance가 7.3일 때 몇 개의 군집으로 나누어지는가?
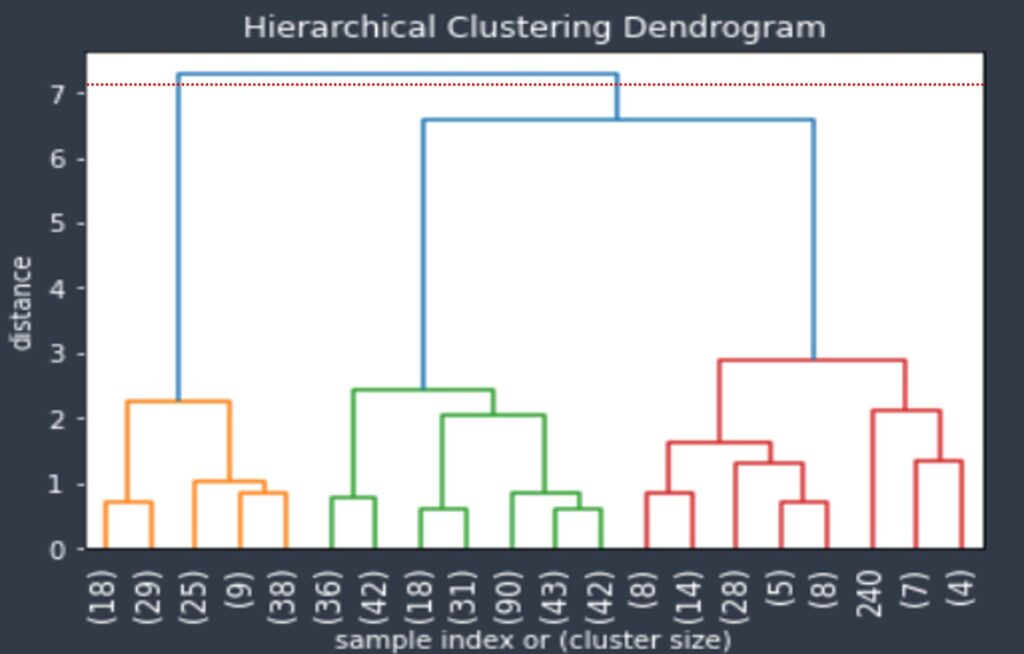
- 2개
- 3개
- 4개
- 5개
정답 : 1번
해설: 덴드로그램에서 군집 개수를 결정하는 방법은 절단선(cut-off line)을 설정하여 교차하는 수직선의 개수를 세는 것입니다.
- 절단선 위치: Distance = 7.3
- 절단선과 교차하는 수직선: 2개
- 첫 번째 클러스터: 왼쪽 큰 클러스터
- 두 번째 클러스터: 오른쪽 클러스터
💡 핵심: 덴드로그램에서 군집 개수는 항상 절단선과 교차하는 수직선의 개수와 같습니다!
42. ARIMA 모형에 대한 설명으로 옳은 것은?
- 비정상성 시계열 데이터에도 직접 적용할 수 있다.
- AR(자기회귀) + I(차분) + MA(이동평균) 모형의 조합이다.
- 계절성을 가진 데이터에는 사용할 수 없다.
- 정상성 시계열 데이터에만 적용 가능하다.
정답: 4번
해설 : ARIMA (AutoRegressive Integrated Moving Average)의 핵심 전제조건은 정상성입니다.
- AR(p): 자기회귀 모형 – 과거 값들의 선형결합
- I(d): 차분(Integrated) – 비정상성을 정상성으로 변환
- MA(q): 이동평균 모형 – 과거 오차들의 선형결합
비정상성 데이터는 차분(I)을 통해 정상화한 후 적용해야 합니다.
💡 핵심: ARIMA는 정상성이 생명! 비정상성 데이터는 차분으로 정상화 후 적용해야 합니다.
43. 인공신경망에서 과적합을 해결하는 방법은?
- Sigmoid 함수 사용
- ReLU 함수 사용 ✅
- 배치정규화 적용
- 은닉층 개수 증가
정답: 2번
해설: ReLU 함수가 과적합을 해결하는 이유:
- 희소성(Sparsity): 음수 값을 0으로 만들어 일부 뉴런을 비활성화
- 단순한 구조: 복잡한 비선형성을 줄여 모델을 단순화
- 기울기 유지: Sigmoid 대비 안정적인 학습으로 과학습 방지
다른 선택지들:
- Sigmoid: 기울기 소실 문제
- 배치정규화: 주로 학습률 저하 문제 해결
- 은닉층 증가: 모델 복잡도 증가로 과적합 악화
💡 핵심: ReLU 함수는 기울기 소실 문제를, 배치정규화는 학습률 문제를 해결합니다!
44. 앙상블(Ensemble) 기법에 대한 설명으로 옳은 것은?
- 배깅은 편향을 감소시키고, 부스팅은 분산을 감소시킨다.
- 배깅과 부스팅 모두 편향을 감소시킨다.
- 배깅과 부스팅 모두 분산을 감소시킨다.
- 배깅은 분산을 감소시키고, 부스팅은 편향을 감소시킨다.
정답: 4번
해설: 배깅(Bagging) – 분산 감소
- Bootstrap Aggregating
- 병렬 처리로 여러 모델을 독립적으로 학습
- 예측 결과를 평균내어 분산 감소
- 대표 예시: Random Forest
부스팅(Boosting) – 편향 감소
- 순차적 학습으로 약한 학습기를 강한 학습기로 변환
- 이전 모델의 오류를 다음 모델이 보완
- 편향 감소, 분산은 증가할 수 있음
- 대표 예시: AdaBoost, XGBoost
💡 기억법: 배깅은 Bagging → Bias 아닌 분산 감소! 부스팅은 편향 감소!
45. 주성분분석(PCA)에 대한 설명 중 옳지 않은 것은?
- 분산이 낮은 것부터 주성분을 선택한다.
- 차원 축소 기법 중 하나이다.
- 변수들 간의 상관관계를 이용한다.
- 고유값이 큰 순서대로 주성분을 선택한다.
정답: 1번
해설: PCA는 분산이 높은 것부터 주성분을 선택합니다.
PCA의 핵심 원리
- 데이터의 분산이 최대인 방향을 찾음 → 제1주성분
- 제1주성분과 직교하면서 분산이 최대인 방향 → 제2주성분
- 순차적으로 분산이 큰 순서대로 주성분 선택
올바른 설명들
- 차원 축소 기법 중 하나 ✓
- 변수들 간의 상관관계(공분산 행렬) 이용 ✓
- 고유값이 큰 순서대로 선택 (고유값 = 해당 주성분의 분산) ✓
💡 핵심: PCA는 높은 분산을 가진 주성분부터 선택하여 정보 손실을 최소화합니다!
46. 빅데이터 분석 프로젝트 진행 시 단계별 수행 작업에 대한 설명 중 옳지 않은 것은?
- 데이터 수집 단계에서는 분석 목적에 따라 다양한 소스에서 데이터를 확보하며, 가급적 데이터 중복이나 노이즈를 줄이는 방향으로 진행한다.
- 데이터 전처리에서는 결측치 대치, 이상치 탐색, 변수 변환을 수행하지만, 복잡한 데이터 변환 기법은 모델 성능 향상을 위해 반드시 적용해야 한다.
- 탐색적 데이터 분석(EDA) 단계는 단순 통계 요약과 시각화에 그치지 않고, 데이터 분포 및 변수 간 관계를 심도 있게 분석하여 분석 방향성을 결정한다.
- 최종 결과 도출 및 보고서 작성 단계에서는 단순 결과 전달을 넘어, 실제 비즈니스 적용 시 고려해야 할 이슈들을 충분히 반영한다.
정답: 2번
해설 : 선택지 2번의 “반드시 적용해야 한다”는 절대적 표현이 잘못되었습니다.
올바른 데이터 전처리 접근
- 선택적이고 적절한 변환 기법 적용
- 검증을 통한 효과 확인 후 적용 결정
- 복잡한 변환이 항상 성능 향상을 보장하지 않음
- 과적합 위험 및 해석력 저하 가능성 고려
KISS 원칙 : Keep It Simple, Stupid
- 목적에 맞는 변환
- 효과 검증 후 적용
- 해석 가능성 고려
- 단순함과 성능의 균형
💡 핵심 : 복잡한 변환이 항상 좋은 것은 아닙니다. 적절한 변환과 검증이 성공의 열쇠!
47. 다음 중 초매개변수와 매개변수에 대한 설명으로 옳은 것은?
- 인공신경망의 가중치는 사용자가 학습 전에 설정하는 초매개변수로, 모델 학습 과정에서 변하지 않는다.
- 인공신경망의 가중치는 학습 데이터로부터 학습되어 자동으로 조정되는 매개변수이다.
- KNN의 이웃 수(K)는 매개변수이며, 학습 과정에서 자동으로 최적화된다.
- 초매개변수는 학습 후 평가 단계에서 결정되는 값으로, 가중치와 편향에 포함된다.
정답: 2번
해설:
| 구분 | 매개변수(Parameter) | 초매개변수(Hyperparameter) |
|---|---|---|
| 정의 | 모델이 학습을 통해 자동으로 조정하는 값 | 사용자가 직접 설정하는 값 |
| 학습 과정 | 학습 중 자동 업데이트 | 학습 전 사전 설정 |
| 결정 주체 | 알고리즘 | 사용자 |
| 변화 여부 | 학습 중 지속적 변화 | 학습 중 고정 |
매개변수 예시
- 인공신경망: 가중치(Weight), 편향(Bias) ✓
- 선형회귀: 회귀계수 β₀, β₁, β₂…
초매개변수 예시
- 인공신경망: 은닉층 수, 학습률, 배치 크기, 에포크 수
- KNN: 이웃 수(K), 거리 측도
- Random Forest: 트리 개수, 최대 깊이
💡 기억법: 매개변수는 컴퓨터가 자동으로 학습하는 “컴매개”, 초매개변수는 사용자가 직접 설정하는 “사초매”
48. 의사결정나무(Decision Tree) 모델의 단점으로 옳은 것은?
- 데이터의 양이 많아지면 적합하지 않음
- 의사결정나무는 변수 간 상호작용을 매우 잘 반영함
- 모델 복잡도가 낮을수록 과적합 위험이 커짐
- 의사결정나무는 데이터 전처리가 반드시 필요하다.
정답 : 1번
해설 : 의사결정나무의 대규모 데이터에서의 한계
- 데이터 증가 → 트리 깊이 증가 → 모델 복잡도 증가
- 계산 효율성 문제: 노드 분할 계산량 급격히 증가
- 과적합 위험 증가: 깊고 복잡한 트리 구조 생성
- 메모리 사용량 증가
다른 선택지들
- 변수 간 상호작용 반영: 제한적 (단점)
- 모델 복잡도와 과적합: 높을수록 과적합 위험 증가
- 데이터 전처리: 상대적으로 적음 (장점)
대용량 데이터 처리 대안
- 앙상블 기법: Random Forest, XGBoost
- 분산 처리: Apache Spark MLlib
💡 핵심: 의사결정나무는 해석력과 사용 편의성은 뛰어나지만, 대용량 데이터에서는 효율성과 과적합 문제로 한계가 있습니다!
49. 다음 중 다중공선성 문제를 해결하는 방법으로 가장 옳은 것은?
- 독립 변수 간 상관계수를 높인다
- 다중공선성 문제를 일으키는 독립 변수를 제거한다.
- 종속 변수와 상관관계가 높은 독립 변수를 제거한다.
- 모델의 복잡도를 인위적으로 낮춘다.
정답: 2번
해설: 다중공선성(Multicollinearity): 독립변수들 간에 강한 선형 관계가 존재하는 현상
문제점
- 회귀계수 추정의 불안정성
- 표준오차 증가 → 통계적 유의성 판단 어려움
- 해석의 어려움
해결 방법
- 변수 제거 (1순위): VIF > 10인 변수 단계적 제거
- 차원 축소: PCA, 요인분석
- 정규화 기법: Ridge, Lasso, Elastic Net
- 데이터 수집 개선: 표본 크기 증가
진단 방법
- 상관계수: |r| > 0.8
- VIF(분산팽창인자): VIF > 10
- 조건지수: CI > 30
💡 핵심: 다중공선성은 독립변수 간 높은 상관관계가 원인이므로, 문제가 되는 변수를 제거하는 것이 가장 직접적인 해결책입니다!
50. 데이터 전처리 과정에서 정규화 후 특정 변수에 대한 두 집단 평균 차이 검정을 수행하려고 한다. 다음 중 올바른 순서로 작업을 나열한 것은?
선택지
- 정규화 → 정규성 검정 → t-검정 실시
- t-검정 → 데이터 정규화 → 정규성 검정
- 정규성 검정 → t-검정 → 정규화
- t-검정 → 정규성 검정 → 데이터 정규화
정답 : 1번
해설: 올바른 데이터 분석 순서: 전처리 → 가정 확인 → 분석
1단계 : 데이터 정규화
- 변수들 간 스케일 차이 해결
- 분석 결과의 객관성 확보
- Min-Max 정규화, Z-score 표준화 등
2단계 : 정규성 검정
- 정규화된 데이터의 분포 형태 확인
- t-검정의 전제조건 검증
- Shapiro-Wilk Test, K-S Test 등
3단계 : 적절한 검정 실시
- 정규분포 만족: t-검정
- 정규분포 위반: Mann-Whitney U Test (비모수 검정)
💡 핵심 : 전처리 → 가정 확인 → 분석 순서가 기본 원칙입니다!
51.Boosting 기법에 대한 설명으로 옳은 것은?
- Boosting은 약한 학습기(Weak Learner)들을 순차적으로 학습시켜 강한 학습기를 만드는 앙상블 기법이다.
- Boosting은 모든 학습기에 동일한 가중치를 부여해 병렬로 학습하는 방식이다.
- Boosting은 하나의 결정트리를 깊게 만들어 과적합을 방지한다.
- Boosting 기법은 부트스트랩 샘플링을 사용하여 각각의 학습기를 독립적으로 학습한다.
정답: 1번
해설: Boosting의 핵심 특징:
- 순차적 학습: 이전 모델의 오류를 다음 모델이 보완
- 가중치 조정: 잘못 분류된 데이터에 높은 가중치 부여
- 점진적 개선: 단계별로 성능 향상
- 편향 감소: 약한 학습기의 한계 극복
Boosting vs Bagging:
| 구분 | Boosting | Bagging |
|---|---|---|
| 학습 방식 | 순차적 | 병렬적 |
| 가중치 | 동적 조정 | 동일 가중치 |
| 샘플링 | 가중치 기반 | 부트스트랩 |
| 목표 | 편향 감소 | 분산 감소 |
| 대표 알고리즘 | AdaBoost, XGBoost | Random Forest |
주요 Boosting 알고리즘
- AdaBoost: 가중치 조정을 통한 성능 향상
- Gradient Boosting: 잔차 학습
- XGBoost: 최적화된 구현
💡 핵심: Boosting은 약한 학습기들을 순차적으로 결합하여 점진적으로 성능을 개선하는 기법입니다!
52.다음 중 ReLU 함수와 관련된 설명으로 옳은 것은?
- ReLU는 기울기 소실 문제가 자주 발생한다.
- ReLU 함수는 음수 입력값에서도 항상 양의 기울기를 가진다.
- ReLU는 활성화 함수 중 계산이 가장 느린 함수이다.
- ReLU는 역전파 과정에서 기울기가 0으로 수렴하는 문제가 없다.
정답: 1번
해설: ReLU 함수: f(x) = max(0, x)
죽어가는 ReLU (Dying ReLU) 현상:
- 음수 입력 → ReLU가 0 출력
- 출력 0 → 역전파 시 미분값 0
- 기울기 0 → 가중치 업데이트 안됨
- 뉴런이 “죽어서” 다시 활성화되지 않음
각 선택지 분석
- 기울기 소실 문제: 음수 영역에서 발생 ✓
- 음수에서 양의 기울기: 음수에서 기울기는 0 ❌
- 계산 속도: 가장 빠른 함수 중 하나 ❌
- 기울기 0 수렴 없음: 음수 영역에서 정확히 0 ❌
해결 방법
- Leaky ReLU: f(x) = max(αx, x) (α=0.01)
- ELU, PReLU, Swish 등
💡 핵심: ReLU는 빠르지만 음수 영역에서 기울기가 0이 되어 죽어가는 ReLU 문제가 발생할 수 있습니다!
53. 다음 나이와 최대심박수 산점도 분석에 대해 맞게 설명한 것은?
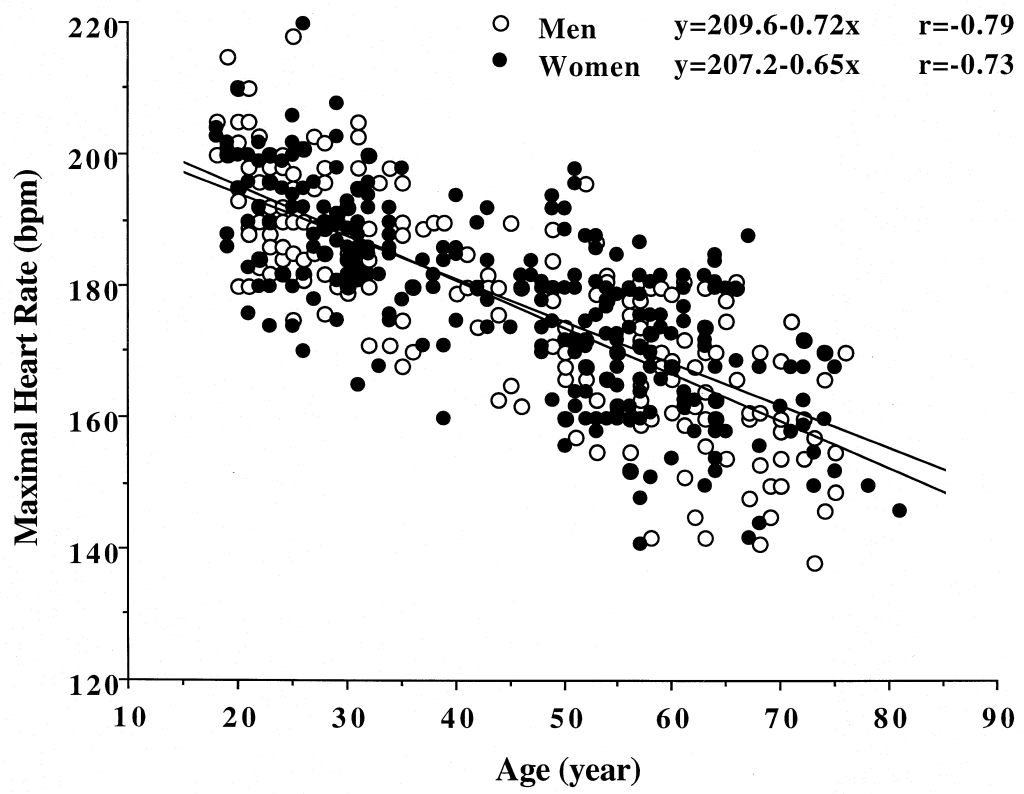
주어진 정보
- 남성: y = 209.6 – 0.72x, r = -0.79
- 여성: y = 207.2 – 0.65x, r = -0.73
- 남성과 여성 모두 나이와 최대심박수 간에 양의 상관관계를 보인다
- 남성이 여성보다 더 강한 음의 상관관계를 보인다
- 여성의 회귀직선 기울기가 남성보다 더 가파르다
- 두 그룹 모두 상관계수가 0.8 이상의 강한 양의 상관관계를 나타낸다
정답: 2번
해설: 상관계수 비교
- 남성: |r| = 0.79
- 여성: |r| = 0.73
- 0.79 > 0.73 → 남성이 더 강한 음의 상관관계
각 선택지 분석
- 양의 상관관계: 두 그룹 모두 음의 상관계수 ❌
- 남성이 더 강한 음의 상관관계: 절댓값 비교 시 맞음 ✓
- 여성 기울기가 더 가파름: |−0.72| > |−0.65| 남성이 더 가파름 ❌
- 0.8 이상 양의 상관관계: 음수이고 절댓값도 0.8 미만 ❌
생리학적 해석
- 일반적 공식: 최대심박수 ≈ 220 – 나이
- 남성: 나이에 따른 최대심박수 감소가 더 뚜렷
- 여성: 상대적으로 완만한 감소
💡 핵심: 상관계수의 절댓값이 클수록 변수 간 관계가 강합니다!
54. 서포트 벡터 머신(SVM) 설명으로 옳은 것은?
- 커널 함수(트릭)를 사용하면 비선형 분류가 가능하다 ✅
- 독립변수를 비선형 변환하면 분류 효율이 올라간다
- 모든 데이터 포인트가 결정 경계 형성에 동일하게 기여한다
- 선형 분리만 가능하여 단순한 문제에만 적용된다
정답: 1번
해설: 커널 트릭의 핵심:
- 저차원 비선형 데이터 → 고차원 공간에서 선형 분리
- 직접 고차원 계산 없이 커널 함수로 효율적 처리
- 복잡한 비선형 분류 문제를 선형 방법으로 해결
각 선택지 분석:
- 커널로 비선형 분류 가능: 완벽한 설명 ✓
- 독립변수 임의 변환: 중복 작업, 비효율적 ❌
- 모든 데이터 포인트 기여: 서포트 벡터만 기여 ❌
- 선형 분리만 가능: 커널 사용 시 비선형 분류 가능 ❌
커널 종류:
- Linear: 선형 분리 가능한 경우
- RBF: 가장 범용적
- Polynomial: 중간 복잡도
- Sigmoid: 신경망 유사 형태
SVM의 핵심 특징
- 서포트 벡터만 결정 경계 형성에 기여
- 마진 최대화로 일반화 성능 향상
💡 핵심: 커널 트릭은 SVM이 비선형 문제를 효율적으로 해결할 수 있게 하는 혁신적 기법입니다!
55. Attention 메커니즘에 관한 설명 중 옳은 것만을 모두 고른 것은?
ㄱ. Attention은 고정된 크기의 벡터에 모든 정보를 압축하려고 하기 때문에 정보 손실이 발생한다
ㄴ. Attention은 디코더가 출력 단어를 예측할 때 인코더의 모든 입력 단어 정보를 참조한다
ㄷ. Attention 스코어는 인코더와 디코더의 은닉 상태를 내적하여 계산한다
ㄹ. Attention은 입력 데이터 중 모든 부분을 동일한 비율로 참고한다
- ㄱ, ㄴ, ㄷ
- ㄱ, ㄹ
- ㄴ, ㄷ
- ㄹ
정답 : 1번
해설
ㄱ. 고정된 크기 벡터 압축으로 정보 손실 ✓
- Attention이 해결하려는 문제
- 기존 Seq2Seq: 전체 입력 → 고정 크기 컨텍스트 벡터 → 정보 손실
- Attention: 각 시점마다 필요한 정보 동적 참조 → 정보 보존
ㄴ. 디코더가 인코더의 모든 입력 단어 정보 참조 ✓
- 디코더 각 시점에서 인코더의 모든 은닉 상태 참조
- 가중합으로 컨텍스트 벡터 동적 생성
ㄷ. Attention 스코어는 내적으로 계산 ✓
- 기본적인 계산 방법
- 디코더 은닉 상태와 인코더 은닉 상태 간 유사도 측정
- 소프트맥스로 정규화하여 확률 분포 생성
ㄹ. 모든 부분을 동일한 비율로 참고 ❌
- 완전히 틀린 설명
- Attention의 핵심은 차별적 가중치 부여
- 중요한 부분에 높은 가중치, 덜 중요한 부분에 낮은 가중치
Attention 동작 과정
- Attention 스코어 계산: e_ij = score(s_i, h_j)
- Attention 가중치 계산: α_ij = softmax(e_ij)
- 컨텍스트 벡터 생성: c_i = Σ(α_ij × h_j)
- 출력 생성: y_i = f(s_i, c_i, y_{i-1})
💡 핵심: Attention은 고정된 벡터 압축의 정보 손실 문제를 해결하기 위해, 디코더가 각 시점마다 인코더의 모든 정보를 차별적 가중치로 참조하는 메커니즘입니다!
56. 다음 중 다중분산분석(MANOVA)을 통해 분석할 수 있는 것은?
- 성별에 따른 키의 차이
- 교육 방법에 따른 수학 점수의 차이
- 학년(1학년, 2학년)에 따른 수학 점수와 국어 점수의 차이
- 나이와 소득 간의 상관관계
정답 : 3번
해설: MANOVA 적용 조건
- ✅ 독립 변수: 범주형 (집단 구분)
- ✅ 종속 변수: 연속형 2개 이상
- ✅ 목적: 집단 간 다중 종속 변수의 평균 차이 검정
각 선택지 분석
- 성별 → 키: 종속변수 1개 → ANOVA 적용
- 교육법 → 수학점수: 종속변수 1개 → ANOVA 적용
- 학년 → (수학점수, 국어점수): 완벽한 MANOVA 사례 ✓
- 나이-소득 관계: 상관분석 적용
선택지 3번 상세
- 독립변수: 학년 (1학년, 2학년) – 범주형 ✓
- 종속변수: 수학점수, 국어점수 – 연속형 2개 ✓
- 검정: 학년에 따른 (수학, 국어) 점수 평균 벡터 차이
MANOVA vs ANOVA
- MANOVA: 여러 종속변수 동시 검정 → 1종 오류율 통제
- 개별 ANOVA: 각각 검정 → 1종 오류율 증가 위험
💡 핵심: MANOVA는 여러 종속 변수의 집단 간 차이를 동시에 검정하는 다변량 분석 기법입니다!
57. 성공 확률을 선형 함수로 변환하여 회귀모형에 적용하는 데 사용되는 변환 기법은 무엇인가?
- 로짓 변환 (logit transformation)
- 오즈비 변환 (odds ratio)
- 로그 변환 (log transformation)
- 제곱근 변환 (square root transformation)
정답: 1번
해설: 로짓 변환 공식 logit(p) = log(p / (1-p)) = log(odds)
변환의 목적
- 확률 p (0~1) → 실수 전체 (-∞ ~ +∞)
- 비선형 확률 → 선형 함수로 변환
- 회귀분석에서 선형 관계 가정 만족
로지스틱 회귀에서의 활용
- 선형 회귀: Y = β₀ + β₁X₁ + β₂X₂ + … + ε
- 로지스틱 회귀: logit(p) = β₀ + β₁X₁ + β₂X₂ + …
각 선택지 분석:
- 로짓 변환: 완벽한 정답 ✓
- 오즈비: 변환 기법이 아닌 해석 도구 ❌
- 로그 변환: 일반적 변환, 확률 변환 부적절 ❌
- 제곱근 변환: 분산 안정화 목적, 로지스틱 회귀 무관 ❌
확률 예측 과정
- 선형 조합: η = β₀ + β₁X₁ + β₂X₂ + …
- 로짓 역변환: p = e^η / (1 + e^η) = 1 / (1 + e^(-η))
- 확률 해석: 0 < p < 1
오즈비 (Odds Ratio)
- OR = e^β (독립변수 1단위 증가 시 오즈 변화율)
- 회귀계수 해석의 핵심 도구
💡 핵심: 로짓 변환은 0~1 범위의 확률을 -∞~+∞ 범위의 실수로 변환하여 선형 회귀의 틀에서 확률을 모델링할 수 있게 하는 핵심 기법입니다!
58. 다음 중 교차검증(Cross-Validation)에 대한 설명으로 옳은 것은?
- 교차검증은 데이터를 여러 개의 부분집합으로 나누어 모델의 일반화 성능을 평가하는 방법이다
- 교차검증은 모델 학습 속도를 빠르게 하는 데 가장 큰 목적이 있다
- 교차검증은 과적합 방지를 위해 항상 데이터를 증강하는 기법이다
- 교차검증은 테스트 데이터와 훈련 데이터를 분리하지 않고 사용하는 방법이다
정답: 1번
해설
교차검증의 핵심 개념
- 데이터를 여러 폴드(fold)로 나누어 여러 번 학습과 검증을 반복
- 모델의 성능을 안정적으로 평가하는 기법
주요 목적
- 🎯 일반화 성능 평가: 새로운 데이터에 대한 예측력 측정
- 📊 성능 안정성: 단일 분할의 편향 제거
- 🛡️ 과적합 방지: 모델의 일반화 능력 검증
각 선택지 분석
- 부분집합으로 나누어 일반화 성능 평가: 완벽한 정의 ✓
- 모델 학습 속도 향상: 정반대, 여러 번 학습으로 더 오래 걸림 ❌
- 데이터 증강 기법: 데이터 증강과 무관 ❌
- 분리하지 않고 사용: 분리가 핵심 ❌
교차검증 종류
- K-Fold CV: 데이터를 K개 폴드로 분할, K번 반복
- Leave-One-Out CV: N-1개 훈련, 1개 검증, N번 반복
- Stratified K-Fold: 클래스 비율 유지하며 분할
장점
- 신뢰성: 단일 분할 편향 제거
- 효율성: 모든 데이터 활용
- 성능 분산: 모델 안정성 측정
주의사항
- 계산 비용: K배 더 많은 학습 시간
- 데이터 누수: 전처리는 각 폴드 내에서 별도 수행
💡 핵심: 교차검증은 데이터를 폴드로 나누어 반복 검증함으로써 모델의 일반화 성능을 신뢰성 있게 평가하는 핵심 기법입니다!
59. 베이지안 정리에서 사전 확률이 사후 확률에 미치는 영향에 대한 설명으로 옳은 것은?
- 사전 확률이 높을수록 사후 확률은 항상 낮아진다.
- 사전 확률과 사후 확률은 독립적이다.
- 사전 확률이 사후 확률 계산에 직접적으로 영향을 미친다.
- 사전 확률은 우도(likelihood)와 동일한 개념이다.
정답 : 3번
해설
베이지안 정리: P(H|E) = P(E|H) × P(H) / P(E)
구성 요소
- P(H|E): 사후 확률 (Posterior)
- P(E|H): 우도 (Likelihood)
- P(H): 사전 확률 (Prior)
- P(E): 증거 (Evidence)
사전 확률의 역할
- 관찰 전 가설에 대한 믿음의 정도
- 사후 확률 계산의 핵심 요소
- 우도와 곱해져 사후 확률에 직접 영향
각 선택지 분석:
- 사전 확률 ↑ → 사후 확률 ↓: 일반적으로 반대 ❌
- 사전 확률과 사후 확률 독립: 직접적 관련 ❌
- 사전 확률이 사후 확률에 직접 영향: 베이지안 정리의 핵심 ✓
- 사전 확률 = 우도: 완전히 다른 개념 ❌
실무 예시
- 의학 진단: 질병 유병률(사전) + 검사 결과(우도) → 진단 확률(사후)
- 스팸 필터: 스팸 빈도(사전) + 단어 출현(우도) → 스팸 확률(사후)
💡 핵심: 베이지안 정리에서 사전 확률은 사후 확률 계산의 핵심 요소로 직접적인 영향을 미칩니다!
빅데이터분석기사 기출 문제 60. 시계열 데이터의 구성 요소 중 불규칙적이고 예측 불가능한 변동을 의미하는 것은?
- 추세(Trend)
- 계절성(Seasonality)
- 순환성(Cyclical)
- 불규칙성(Irregular)
정답 : 4번
해설
시계열 구성 요소
1. 추세(Trend)
- 장기간에 걸친 지속적인 증가 또는 감소 패턴
- 경제성장, 인구 증가 등
2. 계절성(Seasonality)
- 일정한 주기로 반복되는 패턴
- 월별, 분기별, 연별 등 고정된 주기
3. 순환성(Cyclical)
- 불규칙한 주기로 나타나는 장기적 변동
- 경기 순환, 사업 주기 등
4. 불규칙성(Irregular/Random)
- 예측 불가능한 무작위 변동
- 오차항, 잡음(noise) 성격
- 다른 구성 요소로 설명되지 않는 부분
시계열 분해 모델
- 가법 모델: Y(t) = T(t) + S(t) + C(t) + I(t)
- 승법 모델: Y(t) = T(t) × S(t) × C(t) × I(t)
불규칙성의 특징
- 무작위성: 일정한 패턴 없음
- 예측 불가: 통계적 모델링 어려움
- 잡음: 신호와 구별되는 노이즈
- 화이트 노이즈: 이상적인 불규칙성
💡 핵심 : 불규칙성은 다른 체계적 패턴으로 설명되지 않는 무작위적이고 예측 불가능한 변동입니다!
💡 빅데이터분석기사 3과목 핵심 학습 포인트
1. 머신러닝 핵심 개념
- 편향-분산 트레이드오프: 배깅(분산↓), 부스팅(편향↓)
- 매개변수 vs 초매개변수: 자동 학습 vs 사용자 설정
- 과적합 해결: ReLU, 정규화, 드롭아웃, 교차검증
- 앙상블 기법: 배깅(병렬), 부스팅(순차)
2. 통계 분석 기법
- 다중공선성: VIF > 10, 변수 제거가 최우선 해결책
- 주성분분석: 높은 분산부터 주성분 선택
- 로지스틱 회귀: 로짓 변환으로 확률을 선형 함수화
- 분산분석: ANOVA(1개), MANOVA(2개 이상 종속변수)
3. 딥러닝 및 신경망
- 활성화 함수: ReLU의 죽어가는 뉴런 문제
- Attention: 정보 손실 해결, 차별적 가중치 부여
- 역전파: 기울기 소실과 폭발 문제 이해
4. 데이터 전처리
- 올바른 순서: 전처리 → 가정 확인 → 분석
- 정규화: 스케일 차이 해결, 분석 전 필수
- 변환 기법: 목적에 맞는 선택적 적용
5. 모델 평가 및 검증
- 교차검증: 일반화 성능 평가의 핵심
- 성능 지표: 분류(정확도, AUC), 회귀(MSE, R²)
- 과적합 방지: 검증 세트 활용, 조기 종료
📚 추가 학습 권장 사항
- 실무 중심 학습: 이론과 실제 적용 사례 연결
- 최신 기법 업데이트: 트랜스포머, BERT 등 최신 동향
- 코딩 실습: Python/R을 활용한 실제 구현 경험
- 해석력: 모델의 결과를 비즈니스적으로 해석하는 능력
- 윤리적 고려: AI 편향성, 공정성 등 윤리적 측면
본 복원 문제는 기억에 의해 복원된 문제이므로 정확하지 않을 수 있습니다.
함께 읽으면 좋은 글