
빅데이터분석기사 “4과목 빅데이터 결과 해석” 분석
📊 4과목 출제 영역별 분석
모델 검증 & 최적화 (40%)
- 교차 검증: 모델 안정성 평가의 핵심 기법
- Grid Search: 모든 하이퍼파라미터 조합 전수조사
- 과적합 판별: 훈련/검증 오차 패턴으로 진단
- SGD 특성: 노이즈로 인한 수렴 불안정성
평가지표 (25%)
- 회귀: MAE, MSE(제곱 필수!), RMSE, R²
- 분류: F1 Score = 정밀도 × 재현율의 조화평균
- 재현율: 실제 양성 중 정확히 예측한 비율
시각화 (20%)
- 공간데이터: 카토그램(면적 왜곡), 단계구분도(집계), 등치선도(연속값)
- 변수 관계: 산점도, 히트맵 vs 분포: 히스토그램
고급 분석 (15%)
- 로지스틱 회귀: 계수 → 오즈비(e^계수)로 해석
- Lasso 회귀: L1 규제로 변수 자동 선택
- 데이터 품질: 완전성, 유효성, 일관성 등
🎯 빅데이터분석기사 4과목 핵심 포인트
- 수식 정확도: MSE 제곱항, F1 계산식
- 해석 능력: 학습곡선, 로지스틱 회귀 결과
- 개념 구분: 하이퍼파라미터 vs 모델파라미터
- 계산 문제: 교차검증 훈련 횟수 = 조합수 × 폴드수
난이도: 기본개념 60% + 응용계산 25% + 심화해석 15%
빅데이터분석기사 기출 61. 분석 모델의 안정성을 평가하기 위해 훈련 데이터를 여러 서브셋으로 나누어 모델을 반복적으로 검증하는 방법론은?
① 그리드 탐색 (Grid Search)
② 교차 검증 (Cross-Validation)
③ 앙상블 학습 (Ensemble Learning)
④ 정규화 (Regularization)
정답: ② 해설: 교차 검증은 데이터를 여러 부분으로 나누어 일부는 훈련용으로, 일부는 검증용으로 사용하여 모델의 일반화 성능과 안정성을 평가하는 기법입니다.
62. 그리드 탐색(Grid Search)을 이용한 하이퍼파라미터 최적화에 대한 설명으로 가장 옳은 것은?
① 랜덤하게 선택된 일부 조합만 탐색하여 최적의 파라미터를 찾는다.
② 모든 가능한 하이퍼파라미터 조합을 시도하여 가장 좋은 성능을 내는 조합을 찾는다.
③ 이전 탐색 결과를 바탕으로 더 나은 성능을 보일 가능성이 있는 영역을 예측하여 탐색한다.
④ 경사 하강법을 사용하여 최적의 하이퍼파라미터 조합을 찾는다.
정답: ② 해설: 그리드 탐색은 사용자가 지정한 하이퍼파라미터 값들의 모든 조합에 대해 성능을 평가하는 전역 탐색(Exhaustive Search) 방법입니다.
63. 다음 중 학습 곡선(Learning Curve)에 대한 해석으로 가장 적절한 것은? (문제 예시: 학습 곡선 그래프가 주어지며, 훈련 오차와 검증 오차가 모두 낮은 수준에서 수렴하고 더 이상 개선되지 않는 형태)
① 모델이 과대적합(Overfitting) 상태이므로 규제(Regularization)를 강화해야 한다.
② 모델이 과소적합(Underfitting) 상태이므로 더 복잡한 모델을 사용해야 한다. ③ 훈련 데이터가 더 많이 필요하며, 추가 데이터를 확보하면 성능이 개선될 것이다.
④ 모델이 최적으로 수렴하여 더 이상 훈련 데이터가 추가되어도 성능 개선이 거의 불가능하다.
정답: ④ 해설: 훈련 오차와 검증 오차가 모두 낮고 수평적으로 수렴했다면, 모델이 현재 데이터에서 충분히 학습했음을 의미합니다. 이 상태에서는 데이터를 더 추가해도 성능 향상을 기대하기 어렵습니다.
64. 모델 훈련 과정에서 훈련 오차(Training Error)는 계속 감소하지만, 검증 오차(Validation Error)는 특정 시점부터 감소하다가 다시 증가하는 현상이 나타났다. 이 현상을 무엇이라고 하는가?
① 과소적합 (Underfitting)
② 과대적합 (Overfitting)
③ 경사 소실 (Vanishing Gradient)
④ 지역 최솟값 (Local Minimum)
정답: ② 해설: 훈련 데이터에만 너무 잘 맞춰져 새로운 데이터(검증 데이터)에 대한 예측 성능이 떨어지는 현상으로, 과대적합의 전형적인 특징입니다.
빅데이터분석기사 기출문제 65. 확률적 경사 하강법(Stochastic Gradient Descent, SGD)의 특징으로 거리가 먼 것은?
① 전체 데이터가 아닌 일부 샘플(미니배치)을 사용하여 파라미터를 업데이트한다.
② 학습 속도가 빠르고 대용량 데이터 처리에 적합하다.
③ 파라미터 업데이트 시 노이즈가 있어 전역 최솟값(Global Minimum)을 지나칠 수 있다.
④ 항상 전역 최솟값으로 수렴하는 것을 보장한다.
정답: ④ 해설: SGD는 학습 과정의 노이즈(불확실성) 때문에 지역 최솟값(Local Minimum)에 빠질 위험이 있으며, 전역 최솟값으로의 수렴을 항상 보장하지는 않습니다.
66. 하이퍼파라미터(Hyperparameter)에 대한 설명으로 틀린 것은?
① 모델 학습 전에 사용자가 직접 설정해야 하는 값이다.
② 딥러닝 모델의 은닉층 수나 학습률(learning rate)이 이에 해당한다.
③ 모델이 학습 과정에서 스스로 학습하고 업데이트하는 파라미터이다.
④ 그리드 탐색(Grid Search)이나 랜덤 탐색(Random Search)을 통해 최적화할 수 있다.
정답: ③ 해설: 모델이 학습 과정에서 스스로 학습하는 파라미터는 가중치(weight)나 편향(bias)과 같은 모델 파라미터(Model Parameter)입니다. 하이퍼파라미터는 학습에 영향을 주는 외부 변수입니다.
67. 교차 검증(Cross-Validation) 방법 중, 전체 데이터에서 단 하나의 샘플만을 검증용으로 사용하고 나머지를 훈련용으로 사용하는 과정을 모든 데이터에 대해 반복하는 기법은?
① 홀드아웃 (Hold-out)
② K-폴드 교차 검증 (K-Fold Cross-Validation)
③ LOOCV (Leave-One-Out Cross-Validation)
④ 부트스트래핑 (Bootstrapping)
정답: ③ 해설: LOOCV는 데이터의 수(n)만큼 모델을 훈련 및 평가하는 교차 검증 방식으로, 데이터셋이 작을 때 주로 사용됩니다.
68. 10개의 하이퍼파라미터 조합에 대해 최적의 조합을 찾기 위해 10-겹 교차 검증(10-fold cross-validation)을 적용할 경우, 모델은 총 몇 번 훈련되는가?
① 10번 ② 20번 ③ 100번 ④ 1000번
정답: ③ 해설: 각 하이퍼파라미터 조합마다 10번의 훈련(10-fold)을 수행해야 하므로, 총 훈련 횟수는 (하이퍼파라미터 조합 수) x (폴드 수) = 10 x 10 = 100번입니다.
69. 데이터 시각화 방법 중, 표현하려는 수치의 크기에 따라 지도의 행정구역 면적이 왜곡되어 표현되는 시각화 기법은?
① 등치선도 (Isoline Map)
② 점묘도 (Dot Density Map)
③ 단계 구분도 (Choropleth Map)
④ 카토그램 (Cartogram)
정답: ④ 해설: 카토그램은 인구, GDP 등 특정 데이터 값의 크기에 비례하여 지리적 영역의 크기를 왜곡하여 표현하는 지도 시각화 방법입니다.
70. 공간 데이터 시각화에 대한 설명으로 틀린 것은?
① 단계 구분도(Choropleth Map)는 지역별 통계치를 색상의 농도나 패턴으로 표현한다.
② 카토그램(Cartogram)은 통계 값에 따라 지역의 면적을 변형시켜 표현한다.
③ 등치선도(Isoline Map)는 기온이나 고도처럼 연속적인 값을 가진 지점들을 선으로 연결하여 표현한다.
④ 단계 구분도(Choropleth Map)는 특정 지점의 정확한 위치 정보를 표현하는 데 가장 적합하다.
정답: ④ 해설: 단계 구분도는 행정구역과 같은 폴리곤(polygon) 단위의 집계 데이터를 표현하는 데 적합하며, 특정 지점의 정확한 위치를 나타내기에는 부적합합니다.
71. 회귀 모델의 평가지표에 대한 수식으로 틀린 것은? (N: 데이터 수, yi: 실제값, y^i: 예측값)
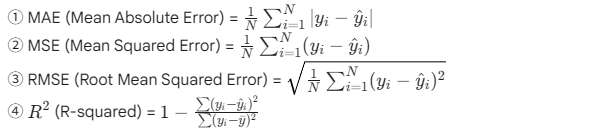
정답: ② 해설: MSE(Mean Squared Error)는 오차의 ‘제곱’ 평균을 의미합니다. 보기 ②번의 수식에는 오차에 대한 제곱(²)이 빠져 있으므로 잘못된 수식입니다. 정확한 수식은
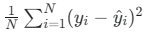
입니다.
72. 분류 모델의 평가지표인 F1 Score를 계산하기 위해 필요한 두 가지 구성요소는?
① 정확도(Accuracy), 특이도(Specificity)
② 민감도(Sensitivity), ROC Curve
③ 정밀도(Precision), AUC
④ 정밀도(Precision), 재현율(Recall)
정답: ④ 해설: F1 Score는 정밀도와 재현율의 조화 평균으로 계산되는 지표입니다. (F1=2⋅Precision+RecallPrecision⋅Recall)
73. 분류 모델의 성능 평가에서 ‘실제 값이 참(True)인 데이터 중에서 모델이 참(True)으로 예측한 데이터의 비율’을 나타내는 지표는?
① 정확도 (Accuracy)
② 정밀도 (Precision)
③ 재현율 (Recall) 또는 민감도 (Sensitivity)
④ 특이도 (Specificity)
정답: ③ 해설: 이는 재현율(Recall) 또는 민감도(Sensitivity)의 정의입니다. (TP / (TP + FN))

74. 다음 중 홀드아웃(Hold-out) 데이터 검증 방법에 대한 설명으로 가장 적절한 것은?
① 전체 데이터를 K개의 부분집합으로 나누어 K번 검증을 수행한다.
② 전체 데이터를 훈련(train), 검증(validation), 시험(test) 데이터셋으로 분리하여 모델을 평가한다.
③ 데이터에서 1개의 샘플만 테스트용으로 사용하고 나머지는 훈련용으로 사용하는 것을 반복한다.
④ 원본 데이터에서 중복을 허용하여 샘플을 뽑아 훈련 데이터를 구성한다.
정답: ② 해설: 홀드아웃은 전체 데이터를 보통 2개 또는 3개의 집합으로 나누어, 훈련에 사용되지 않은 데이터로 모델의 성능을 검증하는 가장 단순한 방식의 검증 기법입니다.
75. 모델의 과대적합(Overfitting)에 대한 설명으로 옳은 것은?
① 데이터의 수가 많을수록 발생하기 쉽다.
② 모델의 복잡도가 낮을 때 주로 발생한다.
③ 훈련 데이터에 대한 성능은 낮지만, 검증 데이터에 대한 성능은 높게 나타난다. ④ 데이터의 수가 적거나 모델이 너무 복잡할 때 발생할 수 있다.
정답: ④ 해설: 데이터의 수가 적으면 모델이 데이터의 특정 패턴이나 노이즈까지 학습하게 되어 과대적합이 발생하기 쉽습니다.
76. 로지스틱 회귀분석 결과표를 해석한 내용으로 틀린 것은? (가상의 결과표 제시 가정) (예시 결과: 변수 ‘자격증 유무’의 p-value=0.01, coef=1.5 / 변수 ‘나이’의 p-value=0.25, coef=0.2)
① 유의수준 5%에서 ‘자격증 유무’는 직업 전환에 유의한 영향을 미친다.
② 자격증을 가진 사람은 가지지 않은 사람보다 직업을 전환할 가능성이 높다.
③ ‘나이’는 직업 전환에 유의한 영향을 미친다고 보기 어렵다.
④ ‘나이’가 한 살 증가할수록 직업을 전환할 확률이 0.2% 증가한다.
정답: ④ 해설: 로지스틱 회귀의 계수(coefficient)는 로짓(logit) 변환된 값으로, 직접적으로 확률의 변화를 의미하지 않습니다. 계수 값에 지수함수(ecoef)를 적용하여 오즈비(Odds Ratio)로 변환해야 해석이 가능합니다. 예를 들어, 계수가 0.2일 때 오즈비는 e0.2≈1.22로, ‘나이’가 한 살 증가할수록 직업 전환에 대한 오즈(odds)가 약 1.22배(22%) 증가한다고 해석해야 합니다. 따라서 확률이 0.2% 증가한다는 해석은 명백히 잘못되었습니다.
77. Lasso 회귀분석이 변수 선택(feature selection) 효과를 가지는 이유로 가장 적절한 것은?
① L2 페널티 항을 사용하여 변수 간의 상관관계를 줄이기 때문이다.
② L1 페널티 항이 일부 변수의 회귀계수를 정확히 0으로 만들기 때문이다.
③ 모든 변수의 회귀계수 크기를 동일한 비율로 감소시키기 때문이다.
④ 결정나무 기반으로 중요하지 않은 변수를 제거하기 때문이다.
정답: ② 해설: Lasso 회귀는 손실 함수에 L1 규제(계수들의 절댓값 합)를 추가하며, 이로 인해 덜 중요한 변수들의 계수가 0이 되어 해당 변수들이 모델에서 제외되는 효과가 있습니다.
78. 데이터 품질(Data Quality)의 주요 관리 차원(Dimension)으로 볼 수 없는 것은?
① 완전성 (Completeness) ② 유효성 (Validity) ③ 일관성 (Consistency) ④ 다양성 (Diversity)
정답: ④ 해설: 데이터 품질의 주요 차원에는 완전성, 유효성, 일관성, 정확성(Accuracy), 적시성(Timeliness), 유일성(Uniqueness) 등이 있습니다. 다양성은 데이터의 특징일 수는 있으나, 품질을 측정하는 관리 차원으로 보기는 어렵습니다.

79. 인포그래픽(Infographic)에 대한 설명으로 가장 거리가 먼 것은?
① 정보, 데이터, 지식을 시각적으로 표현한 것이다.
② 복잡한 정보를 빠르고 명확하게 전달하는 것을 목적으로 한다.
③ 차트, 지도, 다이어그램, 이미지 등 다양한 시각적 요소를 포함한다.
④ 데이터 시각화와는 완전히 다른 개념으로, 데이터 분석 결과를 포함하지 않는다.
정답: ④ 해설: 인포그래픽은 데이터 시각화를 포함하는 더 넓은 개념으로 볼 수 있으며, 종종 데이터 분석 결과를 스토리텔링 형식으로 전달하기 위해 사용됩니다. 데이터 시각화와 완전히 다른 개념이라고 보기는 어렵습니다.
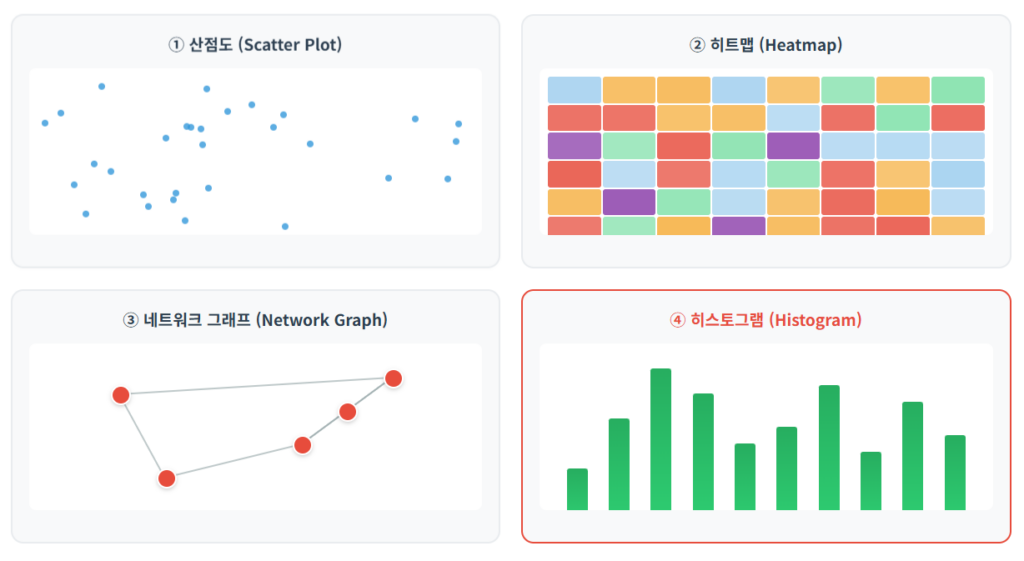
80. 다음 중 변수 간의 관계(Relationship)를 파악하기 위한 시각화 방법으로 가장 거리가 먼 것은?
① 산점도 (Scatter Plot) ② 히트맵 (Heatmap) ③ 네트워크 그래프 (Network Graph) ④ 히스토그램 (Histogram)
정답: ④ 해설: 히스토그램은 단일 변수의 데이터 분포(Distribution)를 확인하기 위한 시각화 방법입니다. 산점도, 히트맵, 네트워크 그래프 등은 두 개 이상의 변수 간 관계를 나타내는 데 사용됩니다.
빅데이터분석기사 10회